Ultra-Fast Ternary LLM Inference on CPUs with Litespark
How ternary weights, SIMD dot-product kernels, and Litespark-Inference make billion-parameter language models practical on Apple Silicon, Intel and AMD.


Large language models have transformed what software can do, but their hardware requirements remain out of reach for most people. Standard inference depends on datacenter GPUs that cost tens of thousands of dollars per unit, or on cloud APIs billed per token. At the same time, there are more than one billion personal computers in use worldwide, most of them equipped with capable CPUs that sit idle as far as AI workloads are concerned.
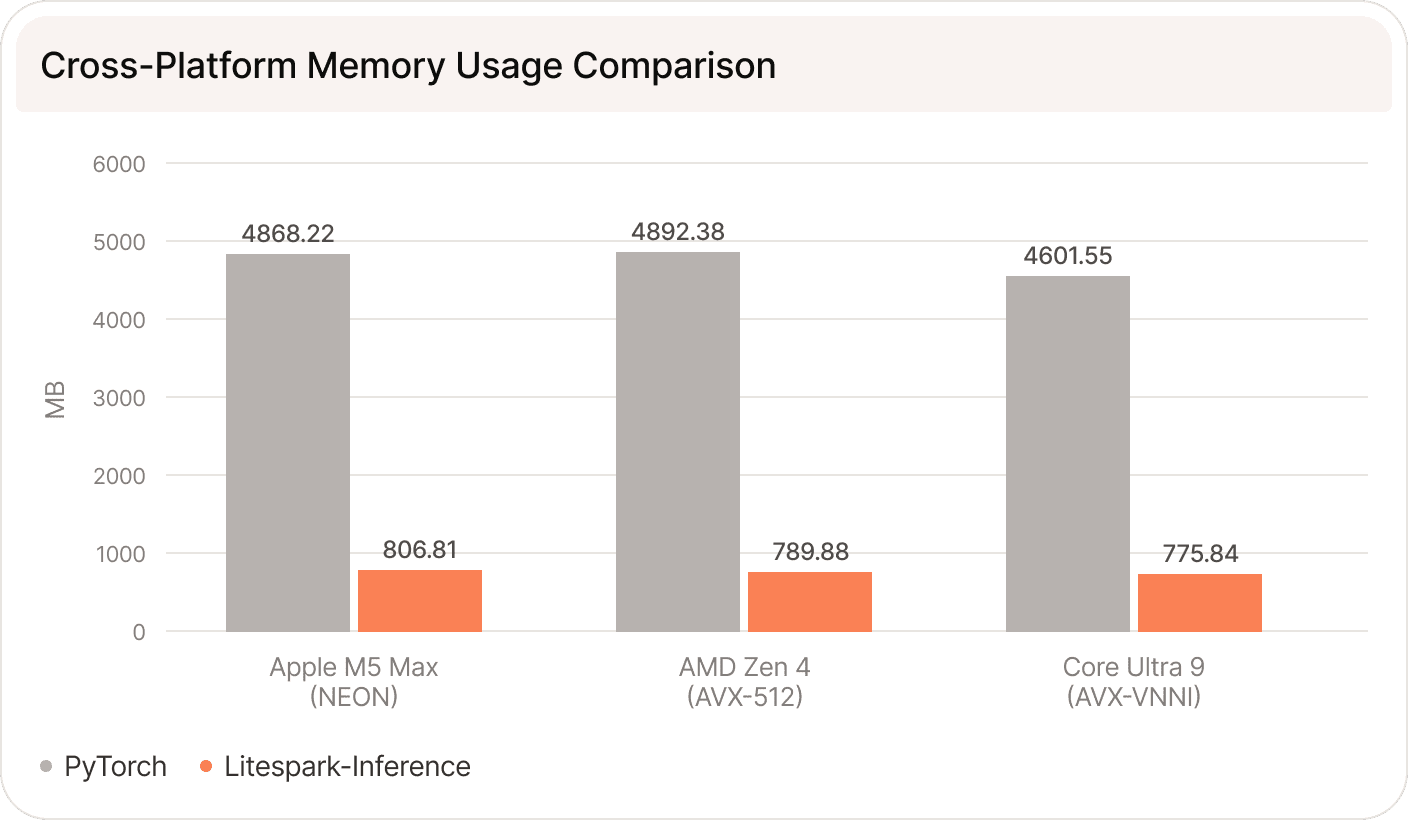
In this post we describe Litespark-Inference, a pip-installable Python library that runs ternary language models efficiently on the CPUs people already own - Apple Silicon, Intel, and AMD. We explain why ternary models make this possible, how we built custom SIMD kernels to exploit them, and what performance we measured on each platform. The short version: compared to standard PyTorch inference, we see 18.15-97.46× higher throughput and approximately 6× reduction in memory, with generation quality that is indistinguishable from the full-precision reference. Time-to-first-token improves by 5.69× to 7.15× across platforms thanks to a batched prefill kernel that amortizes weight loads across the whole prompt.
The challenge: inference on hardware that was not built for it
Running a model locally is appealing for several reasons. It keeps sensitive data on the user's machine, it works offline, it removes per-request latency and cost, and it makes AI accessible where cloud infrastructure is unreliable. For privacy-sensitive applications - health assistants, offline tools, embedded agents - local inference is often the only acceptable option.
The obstacle is performance. Standard inference relies on dense floating-point matrix multiplication, the dominant operation in a transformer. A 2-billion-parameter model in float32 needs roughly 8 GB of memory just for its weights, and even with 4-bit quantization a multi-billion-parameter model produces throughput well below one token per second on a typical CPU. Floating-point multiply-accumulate is simply expensive on hardware that was never designed for sustained neural network workloads.
The question we set out to answer was whether a different class of model, combined with hardware-aware kernels, could make CPU inference fast enough to be genuinely usable.
Ternary models: when multiplication becomes unnecessary
Ternary models take quantization to its theoretical limit. Where common approaches use 16-bit, 8-bit, or 4-bit weights, ternary models constrain every weight to one of three values: {-1, 0, +1}. Microsoft's BitNet b1.58 demonstrated that a 2-billion-parameter model trained natively under this constraint, on 4 trillion tokens, can stay competitive with full-precision models of similar size.
This constraint has a profound consequence. In a standard linear layer each output element is a sum of products, y = Σ xⱼ · wⱼ. When the weights are ternary, no multiplication is needed at all:
Multiplying by +1 is a no-op, multiplying by −1 is a negation, and multiplying by 0 means the term is skipped entirely. The dominant operation in the network collapses from floating-point multiply-accumulate to integer addition and subtraction. This is the property we exploit.
Most existing frameworks do not take advantage of it. Standard PyTorch treats a ternary model as a dense floating-point network, and CPU runtimes such as llama.cpp focus on general 4-bit and 8-bit quantization rather than the specific algebra of ternary weights. The structure is there to be used; the software has to be written to use it.
Why modern CPUs are ready
Reducing the arithmetic is only half the story. To realize the benefit in practice, we need hardware that can perform integer dot products quickly, and modern CPUs provide exactly that through SIMD (Single Instruction, Multiple Data) instructions.
The critical primitive is a family of integer dot-product instructions designed for neural network workloads. On Arm, the NEON sdot instruction - part of the Armv8.2-A DotProd extension - computes the dot product of 16 int8 value pairs and accumulates the result into four int32 lanes, performing 16 multiply-add operations in a single instruction with excellent power efficiency. Arm deployed this capability early: it first appeared in Apple's M1 in 2020 and is now present across billions of Arm-based phones, tablets, and laptops. On x86, Intel introduced AVX-512 VNNI with Ice Lake, and AMD added it with Zen 4; the wider 512-bit registers process 64 int8 pairs per instruction. Intel's Core Ultra processors offer a 256-bit AVX-VNNI variant that handles 32 pairs.
The following table summarizes the instructions we target on each platform.
Because these instructions expect 8-bit integer inputs, they line up almost perfectly with the kind of computation a ternary model needs - provided we feed them data in the right format.
Older x86 CPUs without AVX-512 - including AMD's Zen 2 and Zen 3 generations (Ryzen 3000 and 5000 series, Threadripper PRO 3000 and 5000 series) and Intel chips from before Skylake-X - are supported through an AVX2 + FMA fallback kernel. AVX2 lacks VNNI's single-instruction int8 dot product, so the fallback computes the same operation with a VPMADDUBSW + VPMADDWD pair: meaningfully slower than the VNNI path, but still well ahead of the PyTorch baseline on the same hardware. The AMD Threadripper PRO 5965WX energy numbers reported later in this post were measured on this fallback path.
How Litespark-Inference works
Our kernel design follows three principles: exploit the ternary structure to eliminate multiplication, use hardware dot-product instructions for data-level parallelism, and preserve accuracy through careful quantization and bias correction. The performance-critical kernels are written in C++ and compiled as PyTorch C++ extensions, so they can be called directly from Python with minimal overhead. At import time the library queries the CPU's feature flags and dispatches to the appropriate platform-specific kernel, which means users never have to specify their hardware.
Storing weights as int8
A natural question is how to store ternary weights. Two bits per weight would suffice in principle, but we store them as 8-bit signed integers instead. The reason is practical: the SIMD dot-product instructions we depend on expect 8-bit inputs, so 2-bit packing would require unpacking weights before each computation, negating the benefit.
The cost of this choice is small. A 2-billion-parameter model needs around 500 MB in pure 2-bit packing and around 556 MB as int8 after alignment padding - still a 14× reduction relative to the 8 GB float32 representation. Storing int8 lets us feed weights directly to the hardware dot-product instructions.
Quantizing activations
Weights are ternary, but the activations flowing through the network are continuous floating-point values, so we quantize them to int8 as well. We use per-row symmetric quantization: for each row of the activation matrix - corresponding to one token - we find the maximum absolute value and scale all values into the [-127, +127] range, saving the scale factor so results can be converted back to float32 afterward. This preserves the relative magnitudes within each token's activations.
The computation pipeline
A complete forward pass through a linear layer proceeds in four stages, all fused into a single C++ call to avoid Python overhead and intermediate allocations:
- Quantize the float32 activations to int8 and save the per-row scale.
- Compute the integer dot products with the platform's SIMD instruction.
- Correct the quantization bias. Symmetric int8 quantization can introduce a small zero-point bias, which we remove by subtracting a precomputed weight column-sum from each output. Because the column sums are constant for a given model, we compute them once at load time and reuse them on every inference.
- Rescale the int32 results back to float32 using the saved scale factor.
Numerical accuracy
Integer quantization introduces small numerical differences relative to full float32 computation. We measure this as the maximum logit difference - the largest absolute difference between our int8 output and the float32 reference across all logits - and find it to be approximately 0.68 on the Apple Silicon NEON kernel. In practice this has no observable effect on generation: token selection depends on logit ranking, and a deviation this small does not change which token is chosen. We verified this by generating hundreds of samples with both implementations and confirming the outputs are identical.
Benchmark results
We evaluated Litespark-Inference using Microsoft's BitNet b1.58 2B-4T model, currently the only publicly available ternary model of significant scale. Our baseline is PyTorch with its native CPU backend on each platform, which represents the standard approach of running a ternary model as a dense floating-point network. We report three metrics: peak memory (resident set size), time to first token (TTFT), and sustained generation throughput with KV caching enabled.
Apple Silicon
On an Apple M5 Max, the NEON kernel reduces memory by approximately 6×, allowing the 2B model to fit comfortably on a machine with 8 GB of RAM. Time to first token improves 7.15×, dropping from over 4 seconds to about 0.6 seconds, and throughput increases 18.15× to nearly 40 tokens per second - fast enough that generated text appears effectively in real time.
We also evaluated Litespark-Inference on different Apple chips and the results are summarized below.
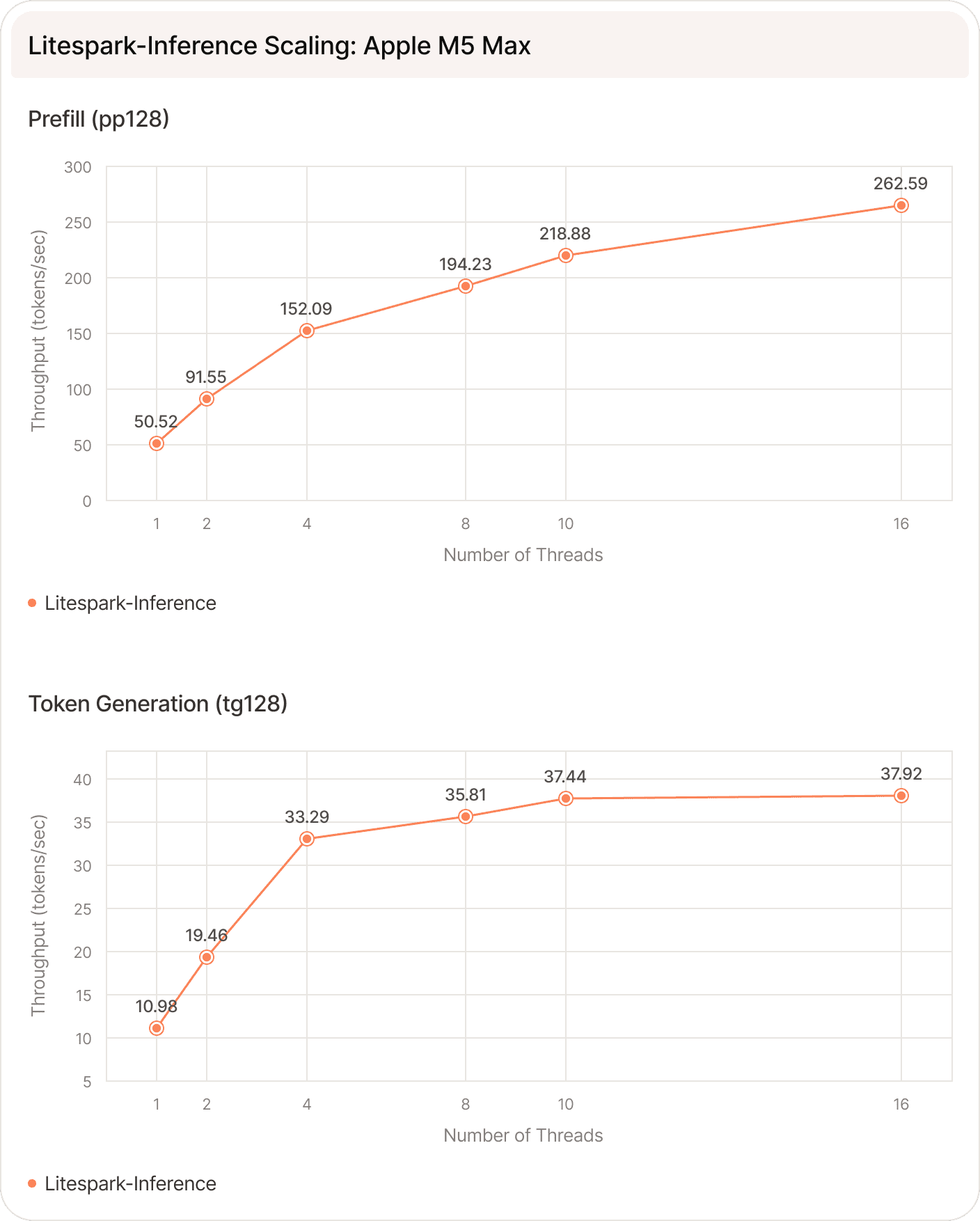
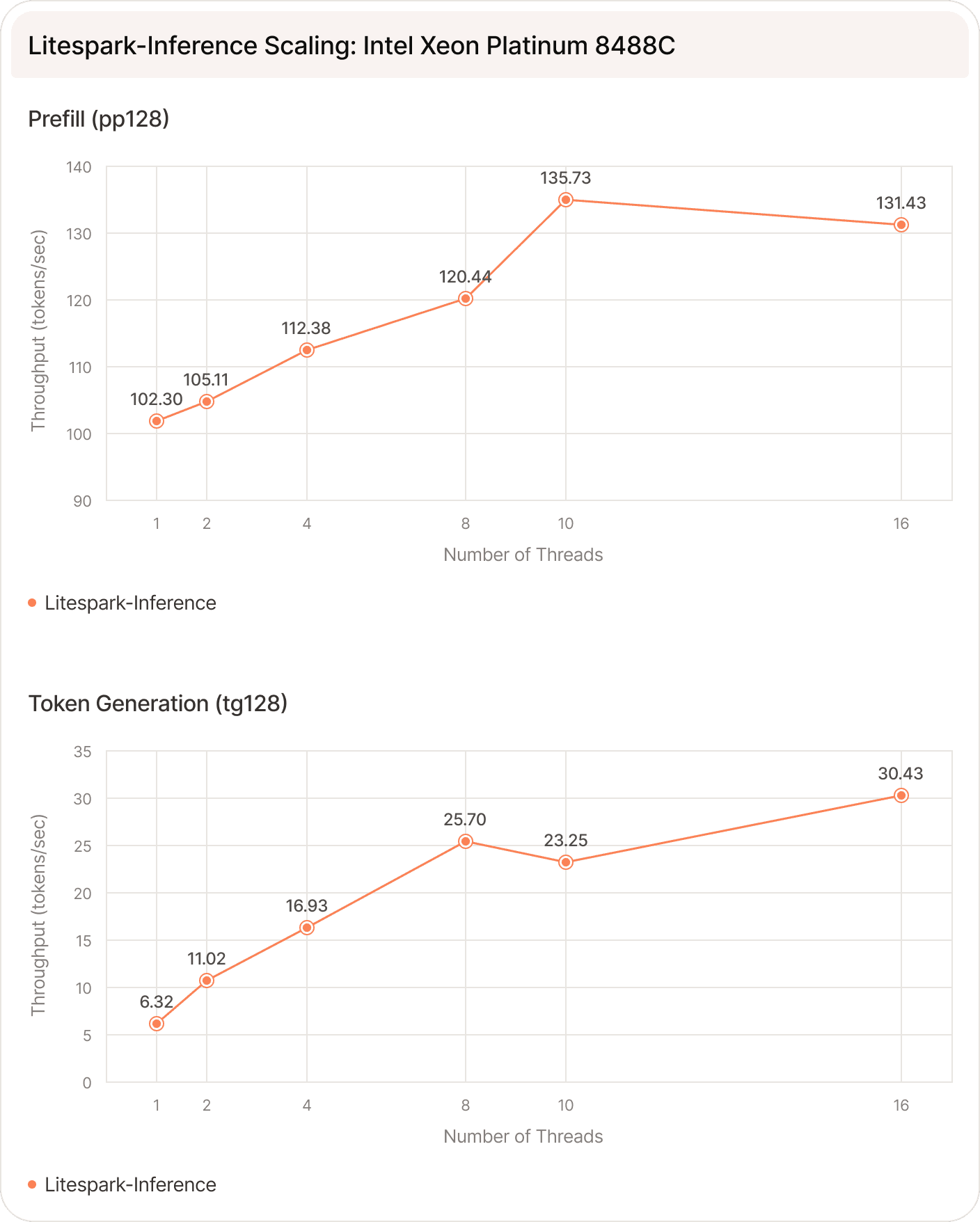
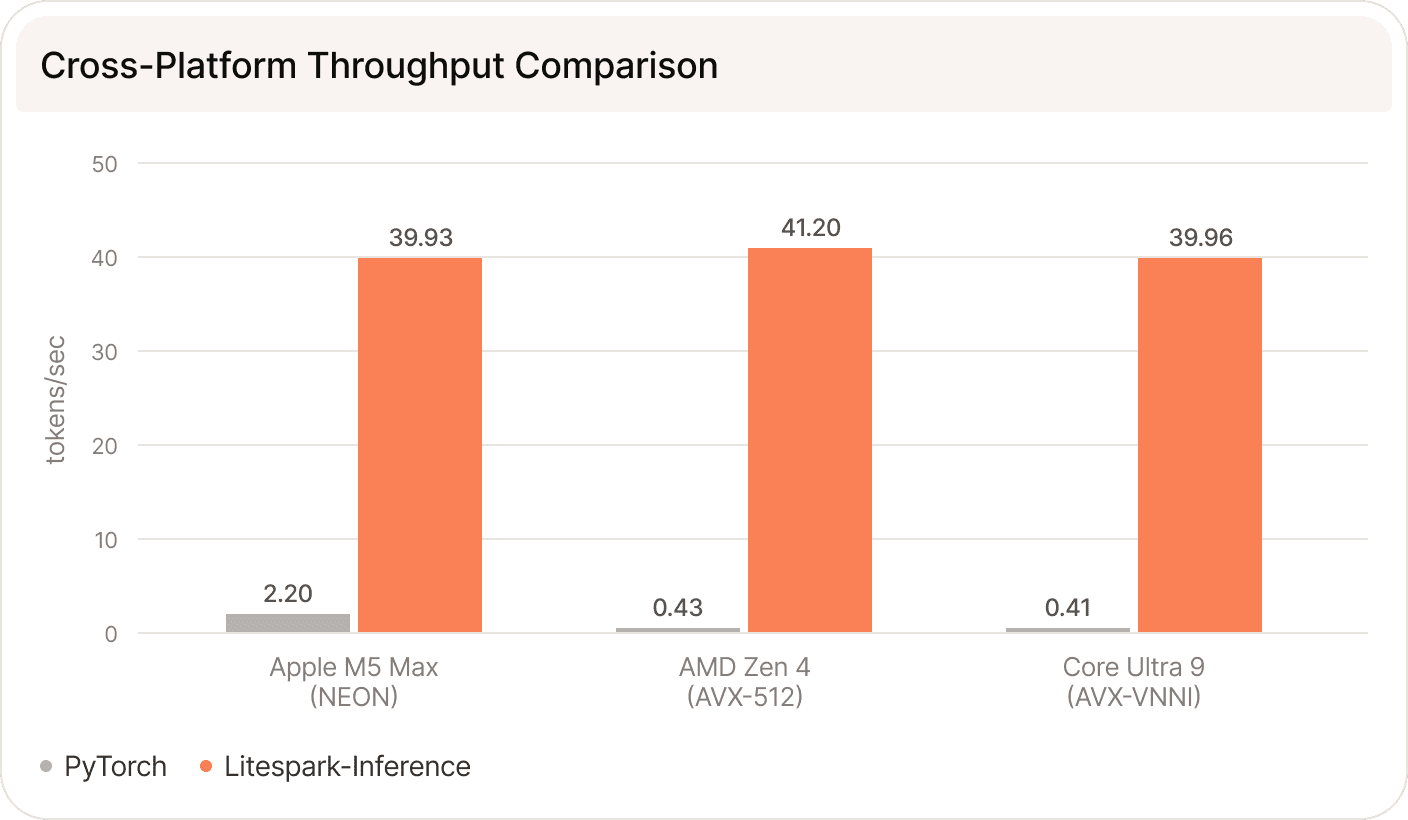
Intel and AMD
Cross-Platform Performance Comparison
Energy consumption
The same throughput advantage shows up directly in the wall-plug energy needed to generate a fixed amount of text. On an Apple M5 Max, Litespark-Inference uses about 0.79 joules per generated token versus 4.74 joules for the PyTorch baseline - a 5.98× reduction that holds steady whether the workload is interactive or batched. The picture is even more pronounced on x86, where the PyTorch baseline runs further from the silicon's peak: on an AMD Threadripper PRO 5965WX, Litespark-Inference uses 7.48 joules per token against 95.11 joules for PyTorch, a 12.71× reduction.
Getting started
A central goal of this work was accessibility. Many efficient inference implementations require specific compiler versions, manual hardware configuration, or a custom build. Litespark-Inference installs with a single command and compiles the right kernel for the host automatically.
On macOS, install OpenMP to enable multi-threaded execution:
Supported models
Litespark-Inference currently supports the following ternary models, all downloaded automatically from Hugging Face:
The package provides both a command-line interface and a Python API. From the command line you can generate a completion, start an interactive chat, or benchmark the current machine:
The Python API integrates with Hugging Face Transformers and follows familiar PyTorch conventions:
Models are downloaded from Hugging Face on first use, converted to the int8 ternary format, and cached locally in ~/.cache/litespark/. This one-time conversion means subsequent loads are near-instant.
Conclusion and next steps
Litespark-Inference shows that ternary networks combined with hardware-aware SIMD kernels can make billion-parameter models practical on the CPUs people already own. Across Apple Silicon, Intel, and AMD we measured 18.15-97.46× higher throughput and approximately 6× memory reduction over standard PyTorch, with a model that fits in well under a gigabyte and generation quality that is indistinguishable from the full-precision reference. The broader lesson is that matching the quantization format to the instructions a CPU actually provides - rather than treating quantization as an approximation of floating-point math - can unlock large performance gains on commodity hardware.
There is more to do. The same Arm NEON kernels that run on Apple Silicon could bring on-device inference to the billions of phones, tablets, and embedded devices built on Arm, where energy efficiency matters most. As larger ternary models become available, the kernels scale naturally and the memory savings grow more valuable. Extending the kernels to the backward pass would enable fine-tuning on consumer hardware, and supporting higher-precision activations would open the door to hybrid quantization schemes.
The library is open source and available now at github.com/Mindbeam-AI/Litespark-Inference. We welcome testing and contributions to support a wider range of hardware and models for the open source AI community.
